ファイル名などを基にして検索することで書誌情報をダウンロードするCalibreのプラグインを自分が持っているPDFの日本語ファイル名に対応するよう試みた。
目次
背景
日本語の書名や著者名、出版社が統一のとれていない形でファイル名に含まれている書籍をスキャンしたPDFファイルがある。それらを電子書籍管理ソフトウェア Calibre で管理しようと思って少し試してみている。
書誌情報をダウンロードする機能として、Amazonの情報をGoogle で検索して、可能ならWebキャッシュから情報を得るようになっていると思われるものが組み込まれている。
少し試してみたが、書誌情報がうまく得られない。原因を調べるとファイル名中の単語をうまく抽出できないためのようであった。日本語の記号などを認識していないようであり、そのために、書名や著者名が連続したキーワードで検索したりしているために、求める書籍情報が検索結果に含まれない。
作成したプラグインの概要
そこで、日本語対応を少し試みるプラグインを作成してみた。テストが不十分なので、とりあえず、ここに記録を残しておく。日本語に対応させたが、英語への対応が十分でなくなったりしている。統合したものを作成すべきと思うが、当面は、日本語対応のプラグインと英語などに対応しているプラグインを併用することで対応することにする。
うまくできるようになった書籍もあるが、自動的にはうまくみつけられない書籍もまだ残っている。もっとも、書名の一部が間違っていたりすると当然ながら適切な情報が得られない。
主な変更点
書籍のタイトルと著者の文字列のトークン化の際に、日本語などCJK文字の記号類を空白に変換して、トークンに分けるようにした。
また、検索結果からの書誌情報では著者や訳者の名前のいずれかが欠落している場合もあったので、元のファイル名に含まれていた情報をコメントに残すようにした。
記号とみなした文字
最後に示すプログラムでは以下の表のCJK関連の文字を記号として、空白に変換し、それを区切りとしてトークンを切り出すようにした。他にも記号として考えられる文字はあるが、自分の日本語ファイル名で使っていないと思われるものは対象外を基本的とした。
Unicode一覧表 (http://www.shurey.com/js/works/unicode.html) を参考にした。
| 区分 | Unicode | 文字 |
| 一般句読点 (General Punctuation) |
U+2000 から U+206F | |
| CJKの記号及び句読点 (CJK Symbols and Punctuation) |
U+3000 から U+3004 U+3006 から U+303F |
空白および 、から〄 と 〆 から 〿 U+3005「々」を除く |
| 囲みCJK文字・月 (Enclosed CJK Letters and Months) |
U+3200 から U+32FF | ㈀ から ㋿ |
| CJK互換用文字 (CJK Compatibility) |
U+3300 から U+33FF | ㌀ から ㏿ |
| 半角・全角形 (Halfwidth and Fullwidth Forms)の全角の記号 | U+FF00 から U+FF65までの右に示す文字 | !"#$%&'()*+,-./:;<=>?@[\]^_`{|}~⦅⦆。「」、・ |
基にした Calibre
基にしたCalibre のバージョンは 4.2.0 である。
GitHubのkovidgoyal/calibre の次のソースを基にしてプラグインを作成してみた。
src/calibre/ebooks/metadata/sources/amazon.py
作成したプラグインの名前は AmazonJP とした。
プラグインのCalibre への組み込み方法
単一のファイルのみで構成されているので、作成したプラグインファイル _init__.py だけを含むZIPファイルを作成する。たとえば、ファイル名を AmazonJP.zip とする。
Calibre の 「設定」の「高度な設定」にある「プラグイン」を選択する。
次に、「ファイルからプラグインを読み込む」を選択する。
プラグインのZIPファイル(ここでは、AmazonJP.zip)を選択する。

次のような確認が出る。「はい」をクリックすることで次に進む。

プラグインがインストールされたら次のようなパネルが表示されるはず。「OK」をクリックすると次に進む。
プラグインの一覧でインストールを確認できる。
「適用」をクリックすることで「設定」のパネルに戻る。
「設定」のパネルの「閉じる」をクリックしてメイン画面に戻る。
プラグインを有効にするためには再起動するようにということなので、再起動を行う。
たとえば、次のようにデバッグモードで再起動する。

プラグインの有効化のしかた
「設定」を開いて「書誌情報のダウンロード」を選択する。
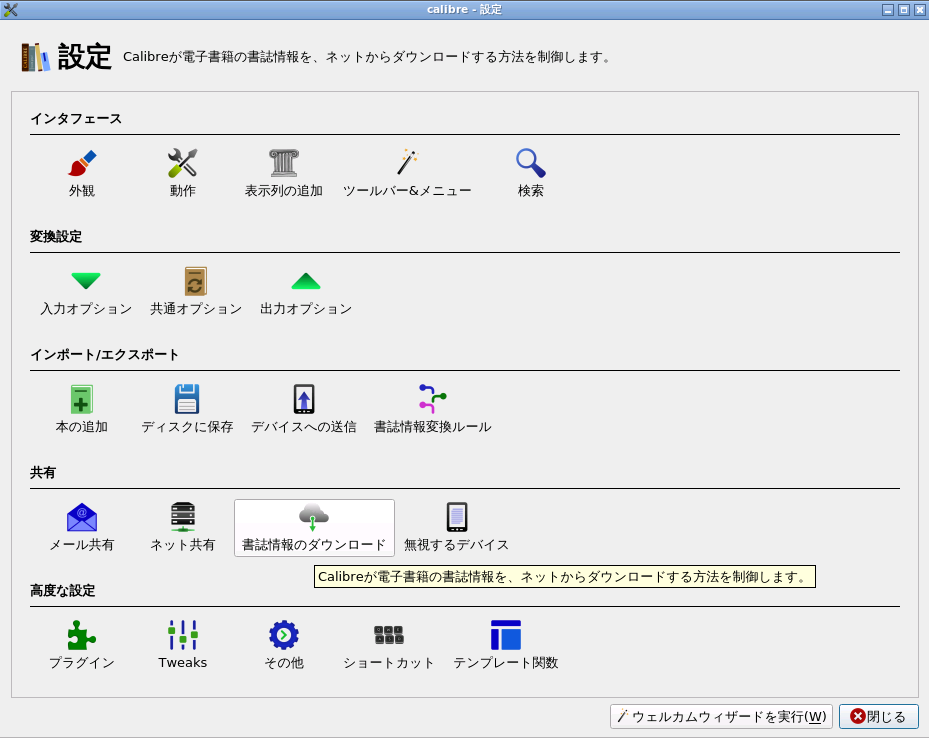
書誌情報のダウンロードに使えるプラグインが表示されるので、必要なプラグインにチェックを入れて選択する。「適用」をクリックし、「設定」パネルも「閉じる」。

書誌情報のダウンロードのしかた
いくつかの方法があるが、簡単なのは、メイン画面で書籍を選択し、Control-D を押すことであろう。
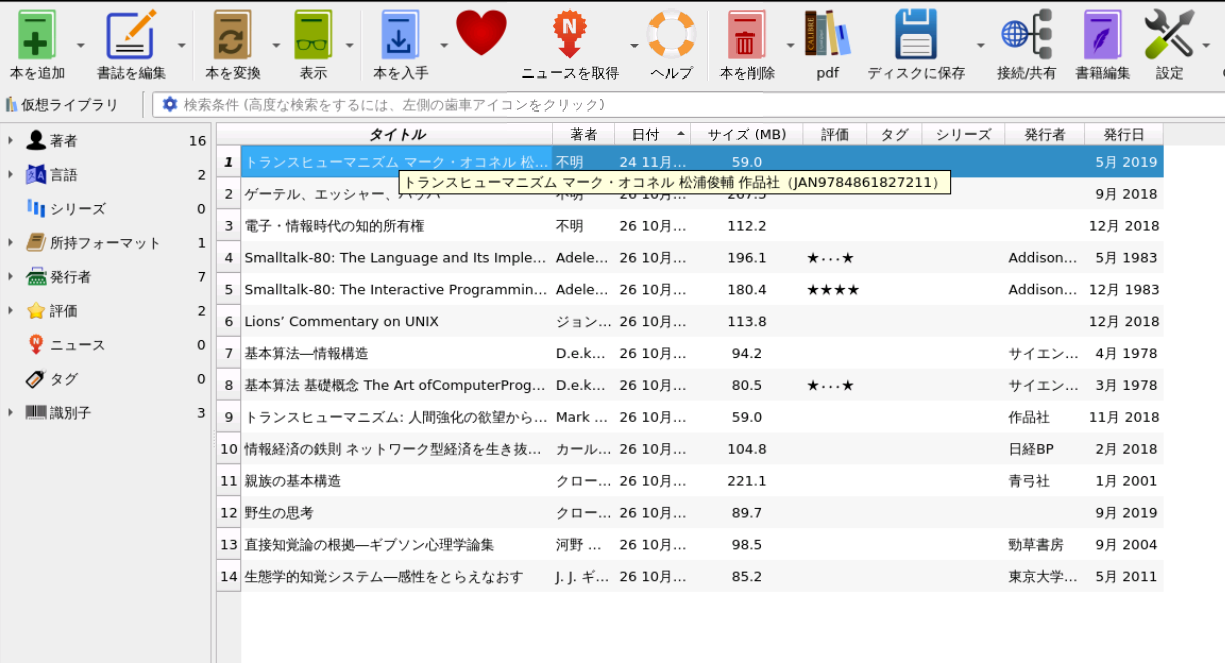
次のようなダイアログが表示されるので、「書誌情報のみのダウンロード」、「表紙のみのダウンロード」、「両方ダウンロード」から必要なものをクリックして選択する。

以下では、「両方ダウンロード」を選択した場合を示す。
しばらすくすると右下に以下のような通知が表示されるはず。
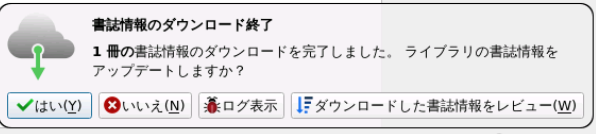
一般に確認が必要と思われるので「ダウンロードした書誌情報をレビュー」をクリックして選択する。
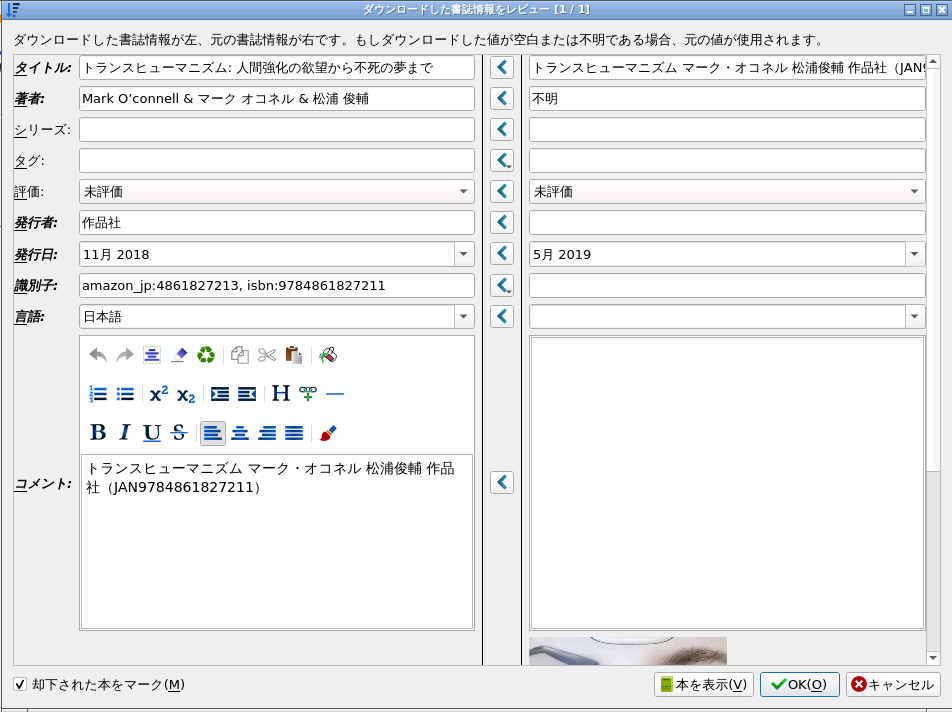
元のデータのままがよければ、その項目の「<」をクリックすると、その内容が左側の更新される情報にコピーされる。
左側は直接修正できても良いと思うが、NASのDockerをWebインタフェースで使っている場合には、ASCIIは入力できるが、日本語などはうまく入力できない(Web browserをつかわないデスクトップアプリであれば大丈夫)。原因と改善方法の調査は今後である。
左側の情報で満足したら、「OK」をクリックして、書誌情報の更新を実際に行う。
作成したプラグインファイル __init__.py
プラグインには __init__.py ファイルが必ず必要であり、ここでは1つのファイルだけを使っているので、ファイル名は「__init__.py」でなければならない。
変更点の前には # kunsen という行があるはず。
#!/usr/bin/env python2
# vim:fileencoding=UTF-8:ts=4:sw=4:sta:et:sts=4:ai
# Based on Amazon plug-in License: GPLv3 Copyright: 2011, Kovid Goyal <kovid at kovidgoyal.net>
# License: GPLv3 Copyright: 2019, kunsen
from __future__ import (unicode_literals, division, absolute_import,
print_function)
__license__ = 'GPL v3'
__copyright__ = '2019, kunsen'
import re
from calibre.ebooks.metadata.sources.amazon import Amazon
from calibre.ebooks.metadata.sources.base import fixauthors, fixcase
from calibre.ebooks.metadata import check_isbn
class AmazonJP(Amazon):
name = 'AmazonJP'
description = 'Downloads metadata and covers from Amazon with removal of specific Japanese characters'
author = 'kunsen'
version = (1, 0, 0)
minimum_calibre_version = (0, 8, 2)
# kunsen
# for saving original title
original_title = None
# for removing Japanese special characters
General_Punctuation = '\u2000-\u206F' # U+2000 to U+206F
CJK_Symbols_and_Punctuation1 = r' 、-〄' # U+3000 to U+3004
# exclude '々' U+3005
CJK_Symbols_and_Punctuation2 = r'〆-〿' # U+3006 to U+303F
Enclosed_CJK_Letters_and_Months = r'㈀-㋿' # U+3200 to U+32FF
CJK_Compatibility = r'㌀-㏿' # U+3300 to U+33FF
Fullwidth_Forms = r'!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~⦅⦆。「」、・'
CJKSymbolsToBeReplaced = '[' + \
General_Punctuation + \
CJK_Symbols_and_Punctuation1 + CJK_Symbols_and_Punctuation2 \
+ Enclosed_CJK_Letters_and_Months + CJK_Compatibility \
+ Fullwidth_Forms \
+ ']'
def create_query(self, log, title=None, authors=None, identifiers={}, # {{{
domain=None, for_amazon=True):
# kunsen
## save originl title
self.original_title = title
return super(AmazonJP, self).create_query(log, title, authors, identifiers, \
domain, for_amazon)
# }}}
def get_title_tokens(self, title, strip_joiners=True, strip_subtitle=False):
'''
Take a title and return a list of tokens useful for an AND search query.
Excludes connectives(optionally) and punctuation.
'''
if title:
# strip sub-titles
if strip_subtitle:
subtitle = re.compile(r'([\(\[\{].*?[\)\]\}]|[/:\\].*$)')
if len(subtitle.sub('', title)) > 1:
title = subtitle.sub('', title)
title_patterns = [(re.compile(pat, re.IGNORECASE), repl) for pat, repl in
[
# Remove things like: (2010) (Omnibus) etc.
(r'(?i)[({\[](\d{4}|omnibus|anthology|hardcover|audiobook|audio\scd|paperback|turtleback|mass\s*market|edition|ed\.)[\])}]', ''),
# Remove any strings that contain the substring edition inside
# parentheses
(r'(?i)[({\[].*?(edition|ed.).*?[\]})]', ''),
# Remove commas used a separators in numbers
(r'(\d+),(\d+)', r'\1\2'),
# Remove hyphens only if they have whitespace before them
(r'(\s-)', ' '),
# Replace other special chars with a space
(r'''[:,;!@$%^&*(){}.`~"\s\[\]/]''', ' '),
##### Japanese character
# Replace Japanese special chars with a space
(self.CJKSymbolsToBeReplaced, ' '),
]]
for pat, repl in title_patterns:
title = pat.sub(repl, title)
tokens = title.split()
count = 0
for token in tokens:
token = token.strip().strip('"').strip("'")
if token and (not strip_joiners or token.lower() not in ('a',
'and', 'the', '&')):
# count = count + 1
if count <= 3 :
yield token
def get_author_tokens(self, authors, only_first_author=True):
'''
Take a list of authors and return a list of tokens useful for an
AND search query. This function tries to return tokens in
first name middle names last name order, by assuming that if a comma is
in the author name, the name is in lastname, other names form.
'''
if authors:
# Leave ' in there for Irish names
remove_pat = re.compile(r'[!@#$%^&*(){}`~"\s\[\]/]')
replace_pat = re.compile(r'[-+.:;,]')
# kunsen
replace_Jpat = re.compile(self.CJKSymbolsToBeReplaced)
if only_first_author:
authors = authors[:1]
for au in authors:
has_comma = ',' in au
au = replace_pat.sub(' ', au)
# kunsen
au = replace_Jpat.sub(' ', au)
parts = au.split()
if has_comma:
# au probably in ln, fn form
parts = parts[1:] + parts[:1]
for tok in parts:
tok = remove_pat.sub('', tok).strip()
## kunsen
if len(tok) > 2 and tok.lower() not in ('von', 'van',
_('Unknown').lower(), _('不明'), '不明'):
yield tok
def filter_result(self, title, authors, identifiers, mi, log): # {{{
if not self.use_search_engine:
return True
if title is not None:
# kunsen
# tokens = {icu_lower(x).rstrip(':') for x in title.split() if len(x) > 3}
tokens = set(self.get_title_tokens(title))
if tokens:
# kunsen
# result_tokens = {icu_lower(x).rstrip(':') for x in mi.title.split()}
result_tokens = set(self.get_title_tokens(mi.title))
if not tokens.intersection(result_tokens):
log('Ignoring result:', mi.title, 'as its title does not match')
return False
if authors:
# kunsen
# Todo: exclude short names
#author_tokens = set()
#for author in authors:]
# author_tokens |= {icu_lower(x) for x in author.split() if len(x) > 2}
author_tokens = set(self.get_author_tokens(authors, only_first_author=False))
# kunsen
# Todo: exclude short names
#result_tokens = set()
#for author in mi.authors:
# result_tokens |= {icu_lower(x) for x in author.split() if len(x) > 2}
result_tokens = set(self.get_author_tokens(mi.authors, only_first_author=False))
if author_tokens and not author_tokens.intersection(result_tokens):
log('Ignoring result:', mi.title, 'by', ' & '.join(mi.authors), 'as its author does not match')
return False
return True
# }}}
def referrer_for_domain(self, domain=None):
domain = domain or self.domain
return {
'uk': 'https://www.amazon.co.uk/',
'au': 'https://www.amazon.com.au/',
'br': 'https://www.amazon.com.br/',
# kunsen
'jp': 'https://www.amazon.co.jp/',
}.get(domain, 'https://www.amazon.%s/' % domain)
def clean_downloaded_metadata(self, mi):
docase = (
mi.language == 'eng' or
(mi.is_null('language') and self.domain in {'com', 'uk', 'au'})
)
if mi.title and docase:
# Remove series information from title
m = re.search(r'\S+\s+(\(.+?\s+Book\s+\d+\))$', mi.title)
if m is not None:
mi.title = mi.title.replace(m.group(1), '').strip()
mi.title = fixcase(mi.title)
mi.authors = fixauthors(mi.authors)
if mi.tags and docase:
mi.tags = list(map(fixcase, mi.tags))
mi.isbn = check_isbn(mi.isbn)
if mi.series and docase:
mi.series = fixcase(mi.series)
if mi.title and mi.series:
for pat in (r':\s*Book\s+\d+\s+of\s+%s$', r'\(%s\)$', r':\s*%s\s+Book\s+\d+$'):
pat = pat % re.escape(mi.series)
q = re.sub(pat, '', mi.title, flags=re.I).strip()
if q and q != mi.title:
mi.title = q
break
# kunsen
# save original title into comments
if mi.comments:
mi.comments += self.original_title
else:
mi.comments = self.original_title
# }}}
__init__.py を含むzipファイル amazonJP.zip を参考までに置いておく。
コメント
入れさせていただきます!
ありがとうございます!
すいません。
プラグインとなるファイルをどのように保存すればいいかを書いていただけれるとありがたいです。
_init__.py だけを含むZIPファイル(たとえば、AmazonJP.zip)を作成して、それを「ファイルからプラグインを読み込む」で読み込んでみてください。
calibre, version 4.2.0
エラー: ハンドルされない例外: InvalidPlugin:The plugin in u'C:\\Users\\\u30df\u30ab\u30c9\\Downloads\\amazon.zip' is invalid. It does not contain a top-level __init__.py file
calibre 4.2 [64bit] embedded-python: True is64bit: True
Windows-10-10.0.18362-SP0 Windows ('64bit', 'WindowsPE')
('Windows', '10', '10.0.18362')
Python 2.7.16+
Windows: ('10', '10.0.18362', 'SP0', u'Multiprocessor Free')
Interface language: ja
Traceback (most recent call last):
File "site-packages\calibre\gui2\preferences\plugins.py", line 319, in add_plugin
File "site-packages\calibre\customize\ui.py", line 472, in add_plugin
File "site-packages\calibre\customize\ui.py", line 61, in load_plugin
File "site-packages\calibre\customize\zipplugin.py", line 194, in load
File "site-packages\calibre\customize\zipplugin.py", line 292, in _locate_code
InvalidPlugin: The plugin in u'C:\\Users\\\u30df\u30ab\u30c9\\Downloads\\amazon.zip' is invalid. It does not contain a top-level __init__.py file
↑がでて上手くいきませんでした。
プログラムをテキストファイルに貼り付けて名前を_init__.py にして、圧縮してZIPファイルに変換し、AmazonJP.zipに名前を読み込ませようとしましたが、おそらく認識してくれてないようです。
作者様のを上手く使えるように、勉強してからまた試してみます。
丁寧にありがとうございました。
申し訳ありません。まず、以前のコメントへの返信の訂正です。ファイル名は本文の記述通り __init__.py でなければなりません。initの前の「_」は2個です。
__init__.py を含む amazonJP.zip をダウンロードできるようにしました。参考になれば幸いです。
当プラグインですが、calibre 5.xにご対応する予定はございませんでしょうか?
4.xで利用させて頂きましたが、バージョンアップで動作しなくなったため、コメントさせて頂いた次第となります
現時点では対応できていませんが、時間があれば対応したいと思います。