vaex による大容量データ処理を Google Colaboratoryを経由してGoogle Cloud Platform (GCP) で試した。
「vaexをColab経由でGCPで試す」と同じ NY Taxiのデータを使っている。
GCPの準備
大容量データyellow_taxi_2009_2015_f32.hdf5 (107GB)をCompute Engine のVMインスタンスからアクセスする形で vaex で処理するための準備をする。
Storageへのデータのアップロード
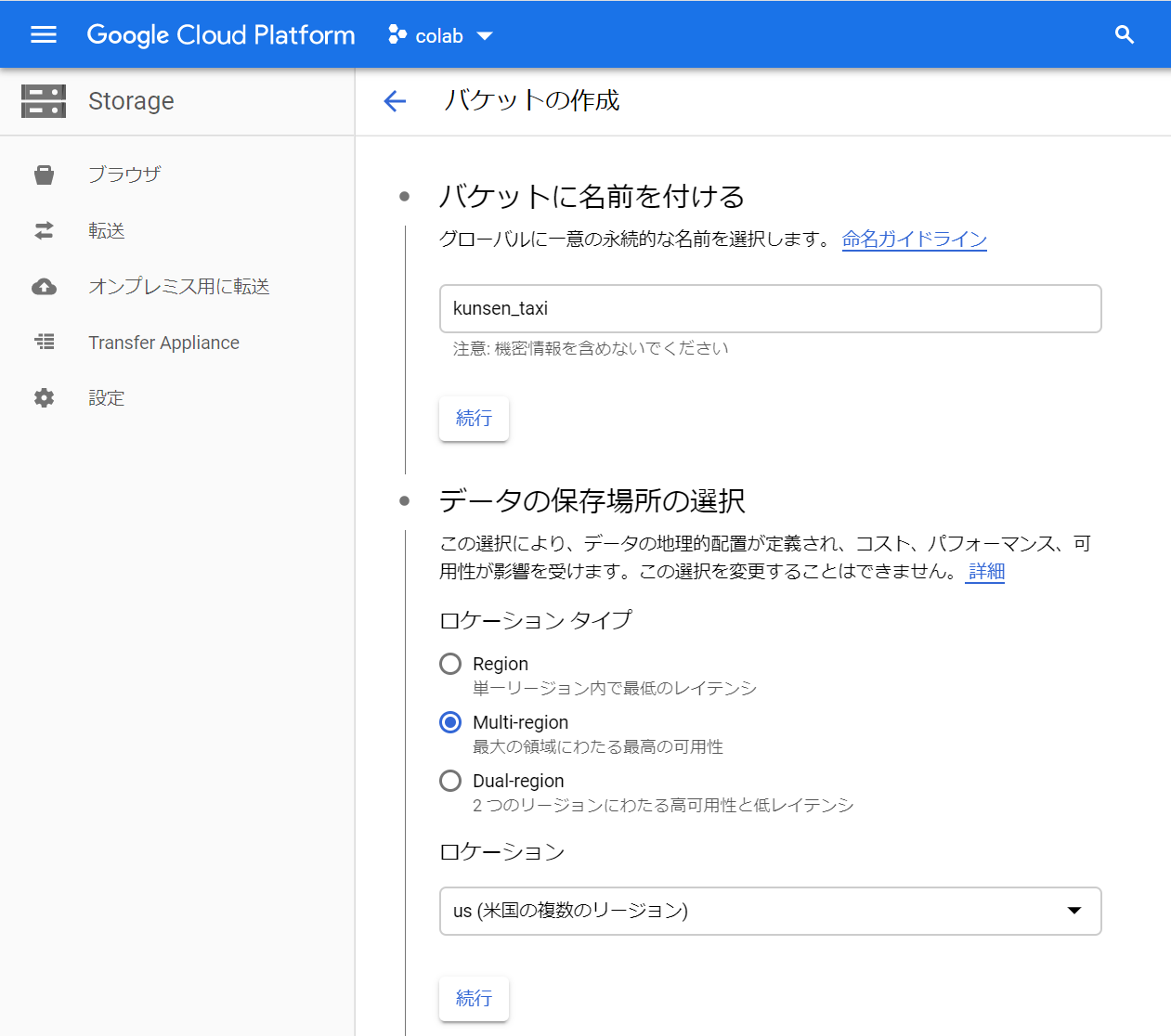
バケットの作成
バケットを作成する。ここでは「kunsen_taxi」という名前にした。
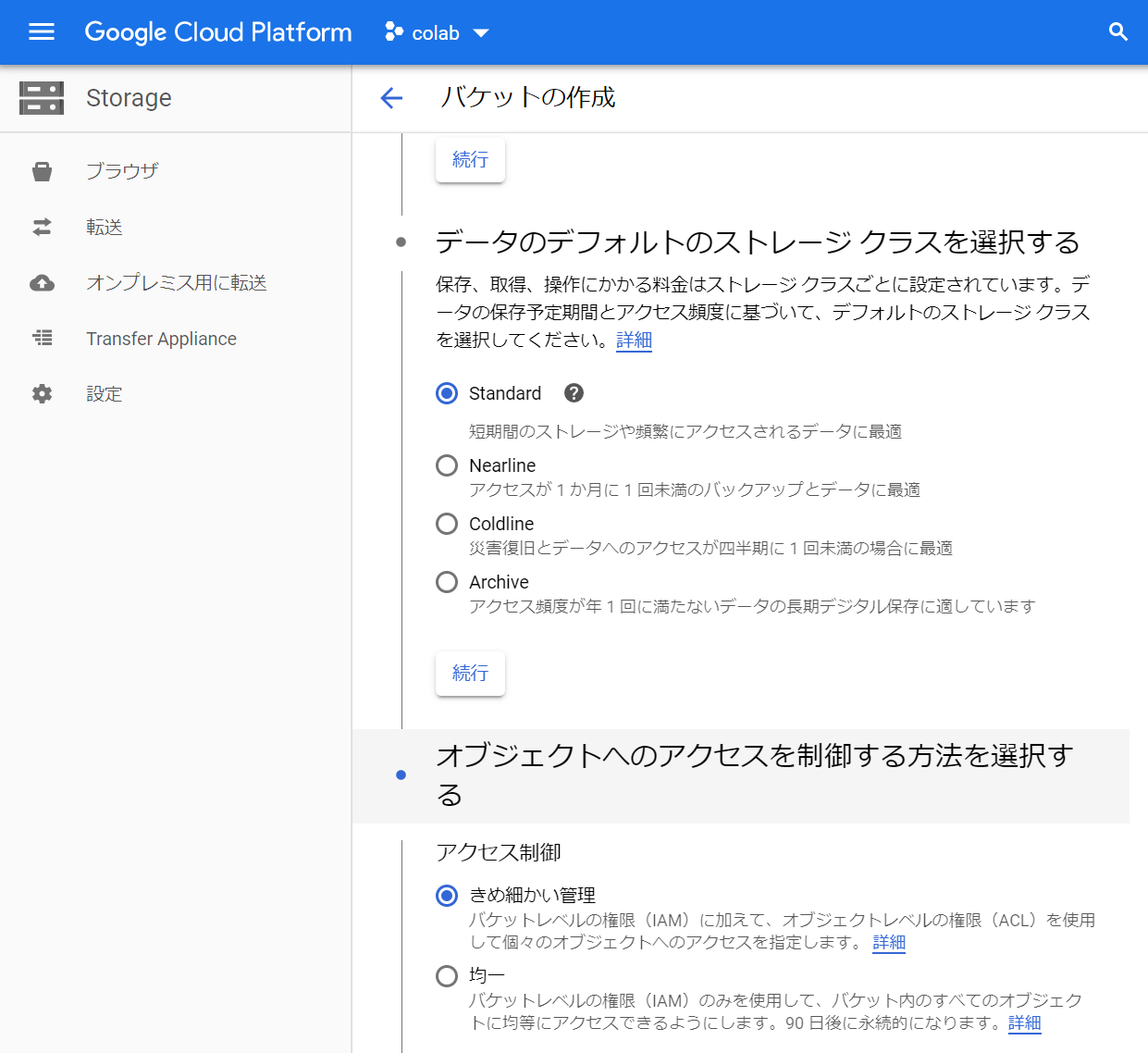
データのアップロード
Google Cloud PlatformのStorage のブラウザから「ファイルをアップロード」を選択してデータをアップロードした。
yellow_taxi_2009_2015_f32.hdf5 (107GB)をそのままアップロードした。半日がかりだった。
圧縮したyellow_taxi_2009_2015_f32.zip (29GB)をアップロードしてから解凍した方がよかったかもしれない。その場合には、VMインスタンス作成の際に、後述の「ストレージ」に対する「読み取り/書き込み」のアクセス権を与えておくことが必要である。
Compute Engine VMインスタンスの作成
Google ColaboratoryのローカルランタイムをGCPで実行するに従ってVMインスタンス colab-taxi-n4-local を作成した。
N1 Standard のCPUを4台とした(メモリは15GB)。N1 Standard の2CPU(メモリ7.5GB)では、ノートブックの途中でメモリ不足となり、正常に処理を完了させることができなかった。
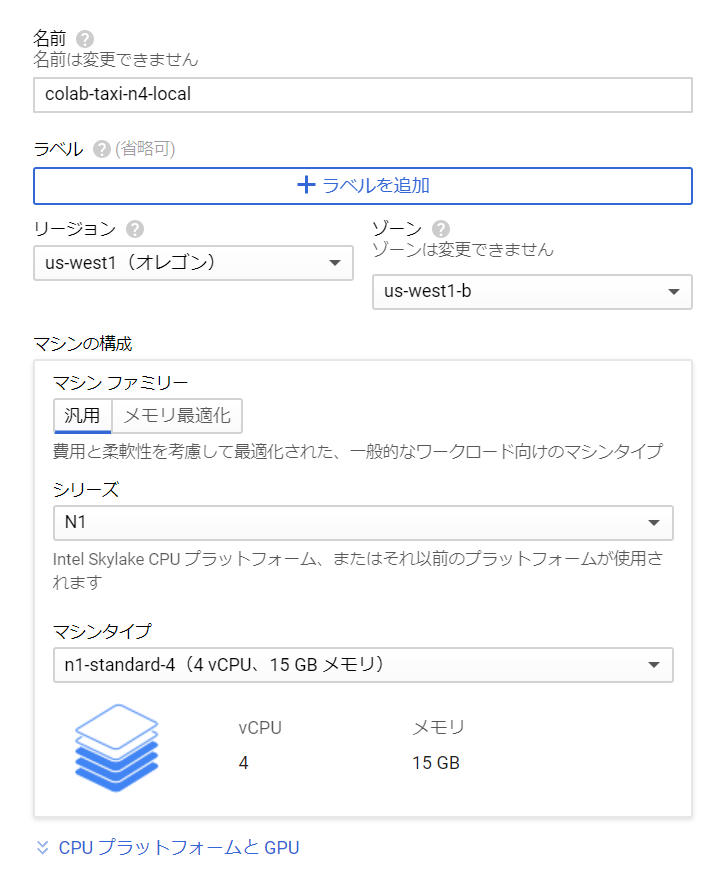
オペレーティングシステムは 「Deep Learning on Linux」、バージョンは 「Deep Learning Image:PyTorch 1.4.0 and fastai m44 」とした。
ディスクサイズは200GBとした。処理対象として考えているデータ(107GB)はローカルドライブに入る。「標準の永続ディスク」を利用した。「SSD永続ディスク」を利用すれば、vaexの処理は「標準の永続ディスク」よりも速くなる。

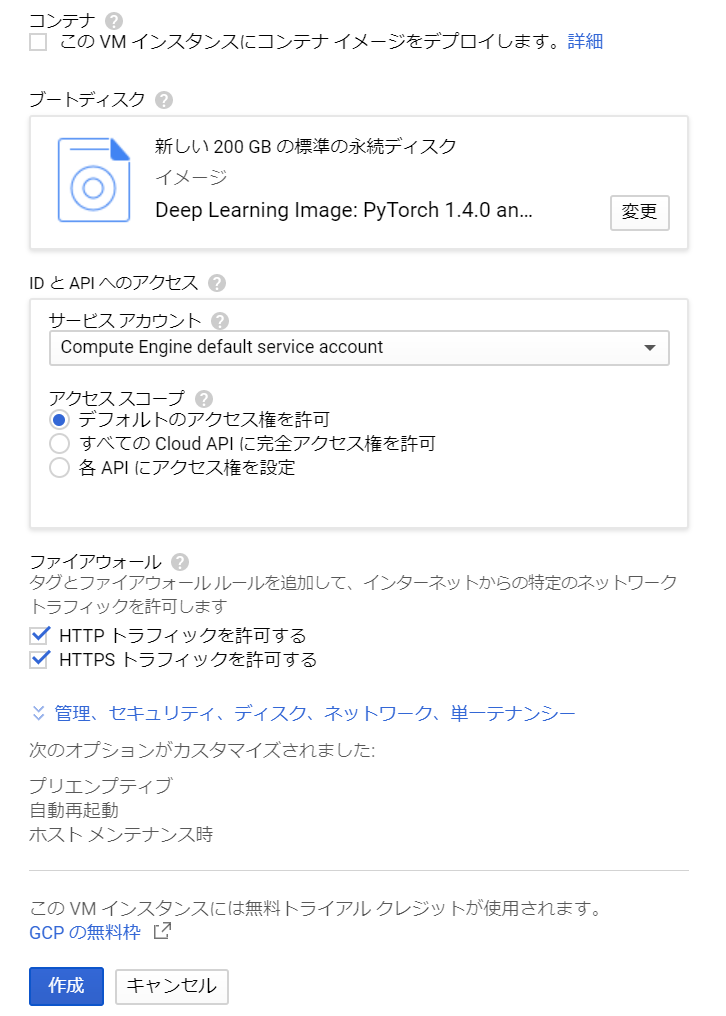
バケットへの書き込み
バケットへの書き込みを行う場合(たとえば、zipを伸張した結果をバケットに保存する場合)には、アクセススコープで「各APIにアクセス権を設定」を選び、表示されるアクセス権のうち「ストレージ」に対して「読み取り/書き込み」をメニューから選択する。これをしておかないとバケットをマウント後に書き込みをしようとしてもエラーとなる。

VMインスタンスの設定
VMインスタンス作成後に(gcloud init で初期化をしてある状態で) Google Cloud SDK Shell から次のコマンドで PuTTYを起動する。
|
1 |
gcloud compute ssh colab-taxi-n4-local |
VMインスタンスを作成した直後は、インスタンスの初期化としてPuTTYで次のコマンドを実行して、Jupyter 拡張機能のインストールと有効化を行う。
|
1 2 |
pip install jupyter_http_over_ws jupyter serverextension enable --py jupyter_http_over_ws |
(別の)Google Cloud SDK Shell から次のコマンドで ポートフォワーディングを設定して、PuTTYを起動する。
|
1 |
gcloud compute ssh colab-taxi-n4-local -- -L 8888:localhost:8888 |
ポートフォワーディングを設定して起動したsshのコンソールから次のコマンドを実行してJupyter notebook サーバーを起動する。
|
1 2 3 4 5 |
jupyter notebook \ --NotebookApp.allow_origin='https://colab.research.google.com' \ --port=8888 \ --NotebookApp.port_retries=0 \ --no-browser |
実行したノートブック
ColaboratoryのVMインスタンスのローカルな標準の永続ディスクにデータをコピーし、それを利用して実行した結果のノートブックが次のファイルである。実行にかかった時間などをファイルに残してある。ただし、vaexのインストールなどはこのノートブックの実行前に行っている。
バケットからSSD永続ディスクにデータをコピーして、それを利用し、実行した結果のノートブックのファイルは次の通り。
ノートブックのコードの主な修正点
主な修正点は次の通り。
vaexのインストール
|
1 |
!pip install vaex PyQt5 vaex-ui |
GCPの「Deep Learning Image:PyTorch 1.4.0 and fastai m44 」では、「vaex を Google Colaboratoryで試す」の時とは違ってvaexのインストール時にエラーは発生していなかった。また、Google Colaboratoryのようにjupyter のカーネルを再起動することも必要なかった。
ローカルドライブにhdf5データファイルを準備する
Storageのバケット kunsen_taxi をマウント
Cloud Storage FUSEを利用して、Google Cloud Storage のバケットを Compute Engine のVMインスタンスにマウントする。後述のように gsutil cp を利用してhdf5ファイルをコピーする場合にはマウント不要である。
|
1 |
gcsfuse kunsen_taxi taxi |
zipを標準のローカルドライブに伸張
次のコードで(Storageのバケットkunsen_taxiにある)ファイル~/taxi/yellow_taxi_2009_2015_f32.zip をローカルドライブのホームディレクトリに伸張する。
|
1 2 3 4 |
%cd ~ !unzip "taxi/yellow_taxi_2009_2015_f32.zip" |
標準の永続ディスクドライブで試したときは、54分34秒(3274秒)かかった。
ローカルドライブにそのままコピー
gsutil cp を利用してStorageのバケットkunsen_taxiにある圧縮していないファイルyellow_taxi_2009_2015_f32.zip.hdf5 をローカルドライブのホームディレクトリにコピーする。 そのままコピーする場合には、Google Cloud Storage のバケットを Compute Engine のVMインスタンスにマウントする必要はない。
|
1 2 3 4 |
%cd ~ !gsutil cp "gs://kunsen_taxi/yellow_taxi_2009_2015_f32.hdf5" ~ |
標準の永続ディスクで試したときは、1時間13分48秒(4428秒)かかった。
永続SSDディスクで試したときは、26分48秒(1608秒)しかかからなかった。
vaex.open
次のコードでローカルドライブのhdf5ファイルをオープンする。
|
1 2 3 |
# Read in the data from disk df = vaex.open('yellow_taxi_2009_2015_f32.hdf5') |
df.describe
標準の永続ディスクで2回試したところ1時間01分41秒(3762秒)と59分47秒(3587秒)かかった。
マウントしたStorageのバケットのデータをそのままopenして利用する場合も試してみたが、3680秒であまり変わらないようだ。
永続SSDディスク上にファイルを置いた場合は、14分39秒(879秒)とかなり短くなった。vaexは、メモリ上にデータをすべて置かず、ファイルを利用するので、ファイルへのアクセス速度がかなり効く。
まとめ
Google Cloud Platformでvaexを使ってみた。
Google Cloud Platformを使う場合には、大量のデータの転送に時間がかかるのがネックである。もっとも、ローカルドライブに1回コピーしておけば永続的に保存できるので、Google Colabと異なり、VMインスタンスの生成のたびに転送を繰り返す必要はない。
当然なことではあるが、ファイルをSSDなどの高速アクセス可能なドライブに置くことでvaexの処理時間を短くできる。